Lesson 09: Structures
Lesson 07: Arrays introduced the array that allows you to group elements of the same type into a single logical entity. To access elements in an array, all that is necessary is that the array's name is given together with the appropriate index value.
The C/C++ language provides another method for grouping elements together. This falls under the name of structures and forms the basis for the discussions in this lesson.
9.1 Structures vs Arrays
A structure in C/C++, defined using the struct keyword, is a user-defined aggregate data type comprising a collection of data members, which can vary in type. Unlike arrays, where all elements must be the same type, the data members in a structure can include a mix of types like int, float, char, or even another struct. This flexibility allows for a more diverse and complex data organization within a single structure.
Motivation for Structures
In programming, we often encounter situations where we need to manage data about various entities or objects. This data can consist of elements of different data types, such as strings, integers, and floating-point numbers. For instance, consider the information associated with a student, which might include name, address, phone number, number of courses taken, fees payable, student ID, and grades obtained.
Traditional Approach Using Arrays
A conventional approach to handling such data is to employ separate arrays for each field and connect them through indices. For example, name[i], address[i], fees[i], and so on would represent the data for the ith student.
Drawbacks of the Array-Based Approach
While this method is straightforward, it becomes cumbersome and unwieldy as the number of fields increases. For instance, passing a student's data to a function using the parameter list would involve passing multiple arrays. Additionally, when sorting the data based on the name field, modifying the data in other arrays would be necessary when exchanging two names.
Introduction of Structures in C/C++
To address these limitations, C and C++ provide structures, which are user-defined data types that enable the grouping of related data items of different types into a single unit. This approach offers several advantages:
- Organized Data Representation: Structures provide a more organized and structured representation of data, making it easier to manage and understand.
- Efficient Memory Usage: Structures allow efficient memory allocation by storing related data items in contiguous locations.
- Simplified Data Manipulation: Structures simplify data manipulation by enabling the access and modification of multiple related data items using a single name.
Example: Student Structure
Consider the following example of a structure representing a student:
struct Student {
string name;
string address;
string phoneNumber;
int numberOfCoursesTaken;
float feesPayable;
string studentID;
char grades[6];
};
This structure defines a data type named 'Student' that encapsulates the relevant information about a student. To access the individual data elements, we can use the dot operator (.) followed by the member name. For instance, student.name would access the student's name.
Advantages of Structures
The use of structures offers several advantages over the traditional array-based approach:
- Improved Code Readability: Structures enhance code readability by grouping related data items together, making it easier to understand the program's structure.
- Reduced Code Complexity: Structures reduce code complexity by eliminating the need to manage multiple arrays and their corresponding indices.
- Enhanced Data Encapsulation: Structures promote data encapsulation by encapsulating related data items within a single unit, restricting direct access to individual members, and promoting controlled access through defined methods.
Structures are a powerful tool in C and C++ for organizing, managing, and manipulating data related to various entities or objects. They offer a more structured, efficient, and maintainable approach compared to the traditional array-based method. By utilizing structures, programmers can create more readable, maintainable, and efficient code.
9.2 Structures
In C++, a structure can contain both functions and data members. The detailed structure in C++ will be discussed in C++ Lesson 02: Classes and Objects.
The format of the struct statement is as follows:
struct structure_name {
type member1;
type member2;
...
} variable_list;
Declare Structure and Structure Variables
A structure variable can either be declared with a structure declaration or a separate declaration like how we declare a variable.
Structure declaration
struct Point { // Structure Declaration
int x;
int y;
};
The above statement defines a new data type (struct Point) that can be used in declaring other variables as below:
struct Point p1, p2, p3;
A variable declaration with a structure declaration.
struct Point { // Structure Declaration
int x;
int y;
} p1; // Define Structure Variable
The above definition actually tells the C compiler two things:
- The first one is the structure of a "struct Point", which can be used to declare another structure variable.
- This statement also declares the variable p1ent.
Since the structure of "struct Point" has been defined, it can be used to declare additional variables:
struct Point p2, p3;
Use of typedef in a structure to shorten the names
We can also use typedef to construct shorter or more meaningful names for structures. The following code shows a new data type named Point, which is synonymous with "struct Point":
typedef struct Point { // Structure Point Declaration
int x;
int y;
} Point; // Data Type Point
We can now declare "structure variables" of type Point, such as the following:
Point p1, p2, p3; // Define Structure Variables
Notice how much shorter and neater this is compared to the following:
struct Point p1, p2, p3; // Define Structure Variables
Since there is hardly any reason to use the "struct Point" form, we could omit Point from the previous declaration and write this:
typedef struct { // Structure Datatype Declaration
int x;
int y;
} Point; // Data Type Name
Structure in Memory
Consider the following statements:
typedef struct { // Structure Datatype Declaration
int x;
int y;
} Point; // Datatype Name
Point p1; // Define Structure Variable
When a structure variable, p1, is declared, the definition reserves enough memory space to hold all the members of p1 — namely x and y. In this case, there will be 4 bytes for each of the two ints. Figure 9.1 shows how p1, p2, and p3 look in memory.
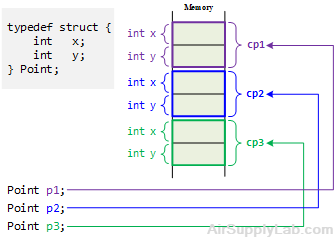
Figure 9.1: Structure Members in Memory
Defining a struct.
Define a struct named PatientData that contains two integer data members named heightInches and weightPounds.
typedef struct{
int heightInches;
int weightPounds;
} PatientData;
Structure for Date
A date consists of three parts: the year, the month, and the day. An integer can represent each of these parts. For example, the "March 4th, 2005" can be represented by the year, 2006; the month, 4; and the day, 4.
typedef struct { // Structure Declaration
int year;
int month;
int day;
} Date;
9.3 Accessing Structure Members and Array of Structures
There are two types of operators used for accessing members of a structure:
- Dot Operator . — Directly accessing the structure members of a structure variable
- Indirection Operator * — Indirectly accessing structure members through a structure pointer
- Arrow Operator -> — Indirectly accessing structure members through a structure pointer
Dot Operator (.) — Direct Accessing
The dot (.) operator is used to access the structure members of a structure variable. Here is how that looks:
typedef struct { // Structure Declaration
int x;
int y;
} Point; // Data Type: Parts
int main(){
Point p1, p2, p3; // Structure Variables: p1, p2, and p3
p2.x = 12;
p2.y = 25;
...
}
Once a structure variable has been defined, its members can be accessed using the dot operator. Line 10 is how the second member is given a value.
p2.y = 25;
The structure member is written in three parts:
- The name of the structure variable (p2)
- The dot operator, which consists of a period (,)
- The member name (y)
This means "the y member of p2."
The variable name must be used to distinguish one variable from another when there is more than one, such as p1, p2, p3, and so on, as shown in Figure 9.2.
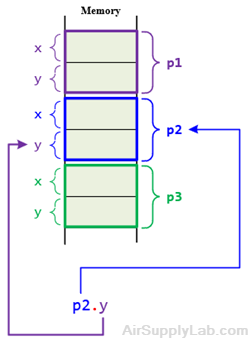
Figure 9.2: The Dot Operator
The structure members are treated just like other variables. In the statement p2.y = 25;, the member is given the value 25 using a normal assignment operator. The program also shows members using in cout or printf statements such as:
cout << "x vale of p2 = " << p2.x << endl;
printf("y value of p2 = %d \n", p2.y);
These statements output the values of the structure members.
Indirection (*) and Arrow Operator (->) — Indirect Accessing
Structure Pointer: Defined as the pointer that points to the address of the memory block that stores a structure is known as the structure pointer.
Syntax of Indirection Operator (*) with Dot Operator (.)
(* pointer_variable) . structure_member = value;
Indirectly access any of the structure members pointed to by the pointer variable.
The parentheses are required because the dot operator (.) has higher precedence than the indirection operator (*).
The -> is called the arrow operator. It is formed by using the minus sign followed by a greater than sign. Simply saying: To access members of a structure, use the dot operator. To access members of a structure through a pointer, use the arrow operator.
Syntax of Arrow Operator (->)
pointer_variable -> structure_member = value;
The operator is used along with a pointer variable. It will assign the value to the variable to which the pointer points.
For example, the following is the declaration for a pointer to a structure:
typedef struct Point { // Structure Datatype Declaration
int x;
int y;
int z;
} Point; // Datatype Name
Point p1; // Define Structure Variable
Point *ptr; // Define Structure Pointer
ptr = &p1;
p1.x = 10;
(*ptr).y = 20;
ptr->z = 30;
- Line 1~5: Define a structure data type named Point
- Line 7: Declared a structure variable to be of type Point.
- Line 8: Declared a variable to be a pointer to a structure Point variable
- Line 10: Take the address of the structure variable p1 and assign it to a structure pointer named ptr
- Line 11: p1 is not a pointer, so the dot operator is the correct member selection operator
- Line 12: Use the indirect accessing operator to access the member of the Point structure pointed by ptr.
- Line 13: Use the arrow operator to access the members of the structure that a pointer variable points to.
9.4 Initializing Structures
Structure Initialization in C/C++
Structures in C serve as a crucial data type that allows you to group related data items of different data types into a single unit. This facilitates a more organized and flexible way to represent complex data relationships. Initializing structures is an essential step in creating and utilizing structure variables.
Individual Assignments
Initializing Structures Using Individual Assignments
One primary method for initializing structures in C involves assigning initial values to each member individually using assignment statements. Consider a structure named Employee with members name, age, and salary:
C Code
struct Employee {
char name[50];
int age;
float salary;
};
C++ Code
struct Employee {
string name[50];
int age;
float salary;
};
To initialize an Employee structure variable named employee1, you can write:
C Code
struct Employee employee1; strcpy(employee1.name, "John Smith"); employee1.age = 35; employee1.salary = 50000.00;
C++ Code
struct Employee employee1; employee1.name = "John Smith"; employee1.age = 35; employee1.salary = 50000.00;
This approach involves individual assignments to each member of the structure.
Initialization List
Initializing Structures Using Initialization Lists
An initializer list provides a more concise and convenient approach to initializing structures in C. It allows you to specify the initial values for all structure members in a single statement. For instance, the previous initialization can be rewritten using an initializer list:
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employee2 = {"John Smith", 35, 50000.00};
This declaration initializes the name, age, and salary members of employee1 with the specified values using a single statement.
Designated Initializers
Initializing Structures with Designated Initializers
Designated initializers provide a more flexible way to initialize specific structure members, even if they are not in the declaration order. You use the member name followed by a colon to specify the value for that member. For example:
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employee3 = {
.name = "Jane Doe",
.age = 32,
.salary = 60000.00
};
This initialization sets the salary member to 60000.00, name to "Jane Doe," and age to 32. The designated initializers allow you to skip members and directly specify specific members' values.
Using Compound Literals
Initializing Structures Using Compound Literals
Compound literals are an alternative to initializer lists for initializing structures in C. They use a similar syntax but are treated as expressions rather than declarations. For instance, the previous initialization can be written using a compound literal:
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employee4 = (struct Employee){
.salary = 60000.00,
.name = "Jane Doe",
.age = 32
};
This expression creates a temporary Employee structure and initializes it with the specified values using a compound literal.
Aggregate Initialization
Initializing Structures with Aggregate Initialization
Aggregate initialization is the most common and straightforward way to initialize structures in C++. It involves using braces {} to enclose the initial values for the structure members. The initialization order should match the declaration order within the structure definition.
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employee5 = {
"Jane Doe",
32,
60000.00
};
In this example, the initialization values are directly assigned to the corresponding structure members based on their order in the Employee structure definition.
Uniform Initialization
Initializing Structures with Uniform Initialization
Uniform initialization provides a consistent and concise way to initialize structures with default values. It uses the = operator followed by a value enclosed in braces. For instance, to initialize all members of Employee to zero, you can write:
C++ Code:
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employee6 = {};
This initialization sets all integer members to zero, all floating-point members to zero, and all pointer members to nullptr.
Initializing structures is an essential aspect of effectively using them in C/C++ programming. Understanding the different initialization methods, including individual assignments, initializer lists, designated initializers, and compound literals, provides flexibility and control in assigning initial values to structure members.
9.5 Bit-Fields in Structure
What Is a Bit-Field
- A bit-field allows you to define structure (or union/class) members that occupy a specified number of bits, rather than the full width of the type.
- Declaration syntax:
type-specifier identifier : width;
e.g., unsigned int flag : 1; defines flag as a 1-bit wide field. - In ANSI C, the type-specifier is typically int or unsigned int; in C++ and specific compilers, other integral types (char, short, long, __int64) may be allowed.
- Bit-fields are useful for memory-efficient flags or mapping hardware registers, but they introduce portability issues (bit order, padding, alignment) and may generate less efficient code.
Syntax & Declaration Rules
- The width must be a constant integer expression.
- In C, the bit‐field type specifier is limited to int/unsigned int; in C++ more types are allowed.
- If a bit‐field is declared without an identifier (anonymous bit‐field), the bits are allocated but cannot be accessed by name — useful for padding or reserved bits.
- A zero‐width bit‐field forces allocation to the next underlying storage unit’s boundary.
- You cannot take the address of a bit‐field member (e.g., &mystruct.x is invalid when x is a bit‐field) because the compiler cannot guarantee it lies on a byte boundary.
Advantages & Limitations
Advantages
- Fine‐grained control of bit‐level fields in structures, saving memory and improving readability for flag fields or hardware registers.
- Access via named members instead of manual bit masks and shifts.
Limitations / Warnings
- The layout of bit‐fields — which bit comes first, packing across storage units, alignment, padding — is implementation‐defined or undefined. Therefore, portability is limited.
- Bit‐fields may lead to less optimal code compared to explicit mask/shift operations.
- You cannot take the address of a bit‐field member, and there are limitations on allowable types and widths.
- For mapping hardware registers (especially volatile registers with strict layout), careful verification of layout and padding is required.
Bit Fields allow the packing of data in a structure. This is especially useful when memory or data storage is at a premium. Typical examples include −
- Packing several objects into a machine word, e.g., 1-bit flags, can be compacted.
- Reading external file formats -- non-standard file formats could be read in, e.g., 9-bit integers.
C allows us to do this in a structure definition by putting: bit length after the variable. For example −
#include stdint.h
/* Assume a hardware control register with the following bit layout:
Bit 0: enable (1 = enable, 0 = disable)
Bits 1–3: mode (0–7)
Bit 4: error flag
Bits 5–7: reserved
Bits 8–15: data field
*/
typedef struct {
unsigned int enable : 1; // bit 0
unsigned int mode : 3; // bits 1–3
unsigned int error : 1; // bit 4
unsigned int : 3; // bits 5–7, unnamed padding
unsigned int data : 8; // bits 8–15
} packet_struct;Here, the packed_struct contains 5 members: Two 1-bit flags (enable and error), one 3-bit mode, one 3-bit unnamed, and an 8-bit data.
C automatically packs the above bit fields as compactly as possible, provided that the field's maximum length is less than or equal to the integer word length of the computer. If this is not the case, then some compilers may allow memory overlap for the fields, while others would store the next field in the next word.
Best Practice Notes
- Always use an unsigned type (e.g., unsigned int, uint8_t) for bit-fields, unless you explicitly need signed behavior.
- Use anonymous (unnamed) bit-fields to skip unused or reserved bits.
- A zero-width bit-field (e.g., unsigned int : 0;) forces the next field to start on a new storage boundary—helpful for register alignment.
- When mapping hardware registers (especially with volatile), verify how your compiler arranges bit order, packing, and alignment. Never assume layout consistency across compilers.
- If the exact bit layout must match hardware, it is often safer to use explicit bit masks and shifts rather than bit-fields. For example:
Using masks provides complete control and avoids compiler-specific alignment issues.#define ENABLE_MASK (1u << 0) #define MODE_MASK (0x7u << 1) #define ERROR_MASK (1u << 4)
The C/C++ standard about bit-field order
The C/C++ standard about bit-field order
The key point:
- The order of allocation of bit-fields within a storage unit is implementation-defined.
This means:
- The compiler decides which bit corresponds to bit 0, bit 1, etc.
- The order (left-to-right or right-to-left) depends on the compiler and target architecture (endianness).
So the C and C++ standards do not define how bits are packed into memory.
They only guarantee that:
- Bit-fields share the same storage unit if they fit.
- You can access them by name in your code (flags.a, flags.b, etc.).
- You cannot portably rely on the binary layout in memory or files unless you know the compiler and target.
How Bit-Fields Are Typically Laid Out
The layout is primarily influenced by two factors:
- CPU Endianness: This is the order of bytes in memory.
- Little-Endian (most common): Systems like x86 (Intel, AMD) store the least significant byte (LSB) at the lowest memory address.
- Big-Endian (less common): Systems like older PowerPC, SPARC, and many network protocols store the most significant byte (MSB) at the lowest memory address.
- Bit-Field Packing Direction: This is the compiler's rule for how to place bits within an allocation unit (like an int or char).
- LSB-to-MSB Packing: The first bit-field defined in the struct is placed in the least significant bits (LSB) of the memory unit. This is common on little-endian systems.
- MSB-to-LSB Packing: The first bit-field defined is placed in the most significant bits (MSB). This is common on big-endian systems.
What compilers actually do
For example:
| Compiler | Architecture | Bit-field order (typical) |
| GCC / Clang | Little-endian x86 / x86_64 | Low-order bits allocated to the first declared bit-field |
| GCC / Clang | Big-endian PowerPC | High-order bits allocated first |
| MSVC | x86 / x64 | Low-order bits allocated first (like GCC on little-endian) |
Illustration with a concrete example
#include <stdio.h>
#include <stdio.h>
struct Example {
unsigned int a : 3;
unsigned int b : 3;
unsigned int c : 2;
};
int main()
{
struct Example e = {1, 2, 3};
unsigned int *p = (unsigned int*) &e;
printf("Raw value = 0x%08X\n", *p);
return 0;
}
Let’s analyze:
- a = 1 → binary 001
- b = 2 → binary 010
- c = 3 → binary 11
Example 1: GCC on Little-Endian (x86_64)
Example 1: GCC on Little-Endian (x86_64)
Typical GCC (little-endian) layout in memory:
bits: 76543210
data: CCBBBAAA
So the raw bits may be:
a = 001 (bit 2..0) b = 010 (bit 5..3) c = 11 (bit 7..6)
→ 0b11010001 = 0xD1 (low byte), depending on alignment.
Example 2: Big-Endian System
Example 2: Big-Endian System
The same structure might map as:
bits: 76543210
data: AAABBBCC
meaning the first field declared gets the highest-order bits in the unit.
Hence, the raw value (0b0010 1011 = 0x2B) could be different even though the code looks the same!
How to Determine the Bit Order on Your System
How to Determine the Bit Order on Your System
Since the order is implementation-defined, the only way to know for sure is to write a test program and observe the result.
The best way to do this is by using a union. A union allows you to access the same block of memory in different ways. You can create a union that contains both your bit-field struct and an integer type (like uint16_t) or a byte array.
Here is a complete C++ program you can run to inspect the memory layout on your machine.
#include <iostream>
#include <iomanip>
#include <cstdint> // For uint16_t, uint8_t
using namespace std;
// 1. Define the bit-field struct we want to test.
// Let's pack 16 bits into three fields: 4, 8, and 4 bits.
struct MyBitFields {
// We use uint16_t as the base type.
// The compiler will pack these into a 16-bit unit.
uint16_t field_a : 4; // First field
uint16_t field_b : 8; // Second field
uint16_t field_c : 4; // Third field
};
// 2. Define a union to inspect the memory.
// This union will let us access the same 16 bits of memory as:
// a) Our bit-field struct (data.bits)
// b) A single 16-bit integer (data.full_int)
// c) An array of two 8-bit bytes (data.bytes)
union BitFieldInspector {
MyBitFields bits;
uint16_t full_int;
uint8_t bytes[2];
};
int main() {
// 3. Create an instance of the union and initialize it to zero.
BitFieldInspector data;
data.full_int = 0; // Clear all 16 bits to 0
// 4. Assign values to the bit-fields by name.
data.bits.field_a = 0x1; // Binary: 0001
data.bits.field_b = 0x23; // Binary: 0010 0011
data.bits.field_c = 0x4; // Binary: 0100
// 5. Print the results in hexadecimal.
// Set up std::cout for hex output
cout << hex << setfill('0');
cout << "--- Bit-Field Layout Inspector ---" << endl;
// Print the 16-bit integer representation
cout << "Full 16-bit integer (hex): 0x"
<< setw(4) << data.full_int << endl;
// Print the raw bytes. This helps visualize endianness.
cout << "Raw bytes (hex): " << endl;
cout << " Byte 0 [Address 0]: 0x"
<< setw(2) << (int)data.bytes[0] << endl;
cout << " Byte 1 [Address 1]: 0x"
<< setw(2) << (int)data.bytes[1] << endl;
return 0;
}
Analysis of Example Output
The output of this program will be different depending on your system. Here are the two most common results.
Case 1: Little-Endian System (e.g., x86: Intel/AMD)
Case 1: Little-Endian System (e.g., x86: Intel/AMD)
On a little-endian machine (like most modern desktops and laptops), the compiler typically packs from the LSB (right) to the MSB (left).
Expected Output:
--- Bit-Field Layout Inspector ---
Full 16-bit integer (hex): 0x4231
Raw bytes (hex):
Byte 0 [Address 0]: 0x31
Byte 1 [Address 1]: 0x42
Memory Breakdown (16-bit view):
The compiler builds the 16-bit integer starting from the least significant bit
| Bits: | 15 14 13 12 | 11 10 9 8 | 7 6 5 4 | 3 2 1 0 |
| Field: | field_c | field_b (high) | field_b (low) | field_a |
| Value: | 0100 | 0010 | 0011 | 0001 |
| Hex: | 4 | 2 | 3 | 1 |
| Result: | 0x4321 | |||
- field_a (4 bits) gets 0x1 →occupies bits 3 ~ 0.
- field_b (8 bits) gets 0x23 → occupies bits 11 ~ 4.
- field_c (4 bits) gets 0x4 → occupies bits 15 ~ 12.
Byte View (Little-Endian): The system stores the least significant byte (0x31) at the first address (bytes[0]) and the most significant byte (0x42) at the next address (bytes[1]).
Case 2: Big-Endian System
Case 2: Big-Endian System
On a big-endian machine, the compiler typically packs from the MSB (left) to the LSB (right).
Expected Output:
--- Bit-Field Layout Inspector ---
Full 16-bit integer (hex): 0x1234
Raw bytes (hex):
Byte 0 [Address 0]: 0x12
Byte 1 [Address 1]: 0x34
Memory Breakdown (16-bit view):
The compiler builds the 16-bit integer starting from the most significant bit
| Bits: | 15 14 13 12 | 11 10 9 8 | 7 6 5 4 | 3 2 1 0 |
| Field: | field_a | field_b (high) | field_b (low) | field_c |
| Value: | 0001 | 0010 | 0011 | 0100 |
| Hex: | 1 | 2 | 3 | 4 |
| Result: | 0x1234 | |||
- field_a (4 bits) gets 0x1 →occupies bits 15 ~ 12.
- field_b (8 bits) gets 0x23 → occupies bits 11 ~ 4.
- field_c (4 bits) gets 0x4 → occupies bits 3 ~ 0.
Byte View (Big-Endian): The system stores the most significant byte (0x12) at the first address (bytes[0]) and the least significant byte (0x34) at the next address (bytes[1]).
Best Practices and Portability
Best Practices and Portability
Because the layout is not guaranteed, you have two main options for writing portable code that deals with specific bit layouts (e.g., network protocols, hardware registers).
Option 1: Manual Bit-Masking (Recommended)
Option 1: Manual Bit-Masking (Recommended)
This is the safest, most portable, and most explicit method. You don't use bit-fields at all. Instead, you use a standard integer and manually manipulate the bits with bitwise operators (&, |, <<, >>).
#include <cstdint>
// Define masks and shifts for our fields
// We are defining our *own* standard, typically big-endian
// Total 16 bits: [ a: 4 | b: 8 | c: 4 ]
#define MASK_A 0xF000 // 1111 0000 0000 0000
#define SHIFT_A 12
#define MASK_B 0x0FF0 // 0000 1111 1111 0000
#define SHIFT_B 4
#define MASK_C 0x000F // 0000 0000 0000 1111
#define SHIFT_C 0
// Function to set field A
void set_field_a(uint16_t* reg, uint16_t value) {
*reg = (*reg & ~MASK_A) | ((value << SHIFT_A) & MASK_A);
}
// Function to get field A
uint16_t get_field_a(uint16_t reg) {
return (reg & MASK_A) >> SHIFT_A;
}
// ... (repeat for fields B and C) ...
This code will work exactly the same way on any C++ compiler and any CPU. When you read/write this uint16_t from a network or file, you only need to worry about byte-swapping (e.g., using htons/ntohs), which is a standard problem.
Option 2: Using Preprocessor Directives
Option 2: Using Preprocessor Directives
If you must use bit-fields, you can mimic what system headers (like for TCP/IP) do: define two different versions of the struct and select the correct one at compile time based on the system's endianness.
// __BYTE_ORDER__ and __ORDER_LITTLE_ENDIAN__ are common macros
// defined by compilers like GCC and Clang.
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
// Little-endian version (LSB-to-MSB packing)
struct MyBitFields {
uint16_t field_a : 4;
uint16_t field_b : 8;
uint16_t field_c : 4;
};
#else
// Big-endian version (MSB-to-LSB packing)
struct MyBitFields {
uint16_t field_c : 4;
uint16_t field_b : 8;
uint16_t field_a : 4;
};
#endif
This is much more complex and still relies on the compiler's packing direction matching the endianness, which is a convention, not a strict rule. Use Option 1 (manual masking) whenever possible.
Padding and alignment rules
Padding and alignment rules
Each bit-field belongs to a “storage unit” (typically the underlying type, e.g., unsigned int).
The compiler can insert padding bits between bit-fields or after them to align to type boundaries.
A bit-field cannot span across the boundary of its base type.
Example:
struct Padded {
unsigned char a : 4;
unsigned int b : 4; // may start on a new 32-bit boundary
};
Here, b will usually not share the same byte as a, because they have different base types.
Forcing a known layout
If you need portable bit-level layout, do not rely on bit-fields!
Instead, do one of these:
Use bit masks and shifts manually:
#define FLAG_A_MASK 0x01
#define FLAG_B_MASK 0x06
#define FLAG_C_MASK 0x18
unsigned char flags;
flags = (1 << 0) | (2 << 1);
Use compiler-specific pragmas or attributes (like #pragma pack, __attribute__((packed)), etc.), but remember: still not portable across compilers.
Example showing the difference between compilers
#include <stdio.h>
struct Bits {
unsigned int x : 1;
unsigned int y : 2;
unsigned int z : 3;
};
int main() {
struct Bits b = {1, 2, 3};
printf("x=%u y=%u z=%u\n", b.x, b.y, b.z);
printf("Raw bytes:\n");
unsigned char *p = (unsigned char*)&b;
for (size_t i = 0; i < sizeof(b); ++i)
printf("%02X ", p[i]);
printf("\n");
}
Compile on GCC (Linux) and MSVC (Windows), and you’ll likely see different raw bytes even though printed fields look identical.
Embedded-System Recommendations (for Raspberry Pi / Coral / Hailo Projects)
Embedded-System Recommendations (for Raspberry Pi / Coral / Hailo Projects)
Given your ongoing embedded and AI-edge work (Raspberry Pi 5, Coral Edge TPU, Hailo-8L, etc.), here are practical recommendations for using bit-fields effectively:
- Hardware Register Access
- Bit-fields can make register definitions easier to read when the hardware layout is well documented and compiler behavior is verified.
- However, since bit ordering and packing differ between compilers (and even between architectures), manual bit masking is safer for portable driver code.
- Cross-Platform Considerations
- On platforms such as ARM (Little-Endian) vs. x86 (Little or Big-Endian), bit-field ordering can change.
- Always test or inspect the compiler’s structure layout (e.g., using offsetof() or static assertions) if you must rely on exact bit placement.
- Performance Awareness
- Compilers often implement bit-field writes as read-modify-write sequences on entire words.
- This can be slower than manual masking/shifting, especially in performance-critical or interrupt-driven code.
- Educational and Demonstration Use
- For teaching purposes, bit-fields are excellent for showing flag grouping and register mapping concepts.
- Use bilingual comments or diagrams to illustrate how each bit represents a hardware or logical flag — this improves student understanding of both structure layout and low-level control.
- Coding Guidelines
- Use volatile for all bit-fields that map to hardware registers.
- Avoid taking the address of a bit-field member (®->enable is invalid).
- Ensure that total width ≤ underlying type’s bit width (e.g., 32 bits for unsigned int on most ARM compilers).
Summary table
| Aspect | Description |
| Bit order within the storage unit | Implementation-defined |
| Endianness of a storage unit in memory | Hardware-defined |
| Padding between fields | Implementation-defined |
| Portable binary layout | No, not guaranteed |
| Safe use case | Internal packed flags, not serialized data |
✅ Bottom line:
- C and C++ leave bit-field ordering up to the implementation.
- You can rely on named access (flags.a) but not on memory layout.
- For binary compatibility or networking, always use masks/shifts explicitly.
9.6 Arrays of Structures
Arrays of structures are a powerful data structure in C/C++ that combines the flexibility of arrays with the organization of structures. They allow you to store multiple instances of a structure in a single array, enabling efficient access to and manipulation of multiple related data items.
Declaring Arrays of Structures
To declare an array of structures in C/C++, you follow the same syntax as declaring an array of any other data type. However, instead of specifying the element data type, you specify the structure type. For instance, to declare an array of 10 Employee structures:
struct Employee {
char name[50];
int age;
float salary;
};
struct Employee employees[10];
This declaration creates an array of named employees with up to 10 Employee structures. Each element in the array represents an individual Employee structure.
Initializing Arrays of Structures
You can initialize arrays of structures using the same methods as initializing individual structures. You can use individual assignments, initializer lists, or designated initializers. For example, to initialize the first element of the employees array:
strcpy(employees[0].name, "John Smith"); employees[0].age = 35; employees[0].salary = 50000.00;
This initializes members' name, age, and salary for the first Employee structure in the array.
Accessing Elements in Arrays of Structures
Accessing elements in arrays of structures is similar to accessing elements in regular arrays. You use the array index followed by the dot '.' operator to access the structure's members. For instance, to access the name of the first employee:
char* firstName = employees[0].name;
This retrieves the value of the name member of the first Employee structure and stores it in the firstName pointer.
Using Range-Based For Loops with Arrays of Structures
Range-based loops in C++ provide a convenient way to iterate over all elements of an array of structures. For example, to print the names of all employees:
for (Employee employee : employees) {
std::cout << employee.name << std::endl;
}
This loop iterates over each Employee structure in the employees array and prints the value of the name member.
Arrays of structures are versatile data structures extending the capabilities of arrays and structures. They allow you to efficiently organize and manage multiple instances of a complex data type, making them valuable for various programming tasks. Understanding how to declare, initialize, and access elements in arrays of structures is essential for effective C/C++ programming.
9.7 Nested Structures
Nested Structure in C: Struct inside another struct
Nested structures, or composite structures, are a powerful data structure in C/C++ that allows you to embed one structure within another. This nesting capability provides a way to organize and represent hierarchical relationships between data elements, making them useful for modeling complex data relationships.
Declaring Nested Structures
To declare a nested structure in C/C++, you define one structure within another. For instance, consider a structure named Student that contains a nested structure named Address:
struct Address {
char street[50];
char city[50];
char state[50];
int zipCode;
};
struct Student {
char name[50];
int age;
float gpa;
struct Address address; // Nested structure 'Address' within 'Student'
};
This declaration creates a Student structure with a nested Address structure. Each Student structure can now hold information about a student's address, including street, city, state, and zip code.
Accessing Nested Structure Members
To access members of a nested structure, you use the dot (.) operator twice. For instance, to access the city member of the address structure within a Student variable named student1:
char* city = student1.address.city;
This statement retrieves the value of the city member of the nested address structure within the student1 structure.
Passing Nested Structures as Arguments
You can pass nested structures as arguments to functions. When passing a nested structure, you pass the entire structure that contains the nested structure. For example, to define a function that takes a Student structure as an argument:
void printStudentDetails(struct Student student) {
std::cout << "Student Name: " << student.name << std::endl;
std::cout << "Student Age: " << student.age << std::endl;
std::cout << "Student GPA: " << student.gpa << std::endl;
std::cout << "Address: " << std::endl;
std::cout << " Street: " << student.address.street << std::endl;
std::cout << " City: " << student.address.city << std::endl;
std::cout << " State: " << student.address.state << std::endl;
std::cout << " Zip Code: " << student.address.zipCode << std::endl;
>}
This function takes a Student structure as input and prints the student's details, including their address information.
Nested structures provide a powerful mechanism for organizing complex data relationships in C/C++. They allow you to embed structures within other structures, creating a hierarchical representation of data. Understanding how to declare, access, and pass nested structures is essential for effectively modeling and manipulating complex data in C/C++ programming.
9.8 Understanding the Differences between C and C++ Structures
C structures and C++ structures, both fundamental data structures in their respective languages, share similarities in their purpose of data organization. However, they exhibit key distinctions that set them apart in terms of functionality and flexibility. This article delves into the differences between C and C++ structures, highlighting their unique capabilities and limitations.
C Structures
C structures are simple data aggregates that allow you to group related variables together. They consist solely of data members and do not support functions.
- Data Members: C structures can only contain variables of different data types. Member functions are not allowed.
- Declaration: The 'struct' keyword is mandatory when declaring the objects of a structure.
- Member Initialization: Member variables cannot be initialized directly within the structure definition.
- Static Members: C structures do not support static members.
- Pointers vs. References: Only pointers can be used to access structure members. References are not supported.
- Empty Structure Size: The compiler assigns a size of 0 to an empty structure in C.
- Data Hiding: C structures do not provide data hiding mechanisms, making all members accessible directly.
- Access Modifiers: Access modifiers, such as 'private' and 'public', are not applicable to C structures.
C++ Structures
C++ structures are more versatile than C structures. They can incorporate both data members and member functions, enhancing their functionality.
- Member Functions: C++ structs can include member functions, allowing for operations directly associated with the structure.
- Declaration: The 'struct' keyword is optional when declaring objects of a structure.
- Member Initialization: Member variables can be initialized directly within the structure definition using in-class initialization.
- Static Members: C++ structs support static members, enabling shared data among structure instances.
- Pointers vs. References: Both pointers and references can be used to access structure members, providing flexibility.
- Empty Structure Size: The compiler assigns a size of 1 to an empty structure in C++ to accommodate the structure's overhead.
- Data Hiding: C++ structs support data hiding through access modifiers like 'private' and 'public', restricting access to structure members.
- Access Modifiers: Access modifiers, such as 'private' and 'public', are used to control access to structure members, enhancing encapsulation.
In summary, C++ structures offer more advanced features than C structures, making them a more powerful tool for data organization and manipulation.